




We Stress-Tested GPT-5.4 Before Launch. Here's What Happened.
OpenAI gave us early access to GPT-5.4 before it launched. We did what any reasonable team would do: threw it at our hardest production workflows and watched what happened. 65 sessions. 2,256 LLM calls. Five team members independently testing. Three pre-release snapshots over two days.
Then our own AI agent, Captain Capy, crawled through every Slack message, pulled production traces from ClickHouse, and auto-generated a 12-page evaluation report that we sent straight to OpenAI.
This is what we found.
TL;DR
- We tested 3 pre-release GPT-5.4 snapshots inside Capy's dual-agent system over 48 hours
- Speed is real: ~2x faster at p95 compared to our Claude Opus 4.6 baseline
- Strengths: system prompt adherence, clean code style on isolated problems, concise output
- Weaknesses: codebase grounding in large repos, long-horizon planning, knowing when to stop iterating
- GPT-5.4 is now available in Capy, try it yourself
How we tested
Capy uses a dual-agent architecture: Captain plans and orchestrates, Build writes code. Both are powered by LLMs with 50+ tools each. We tested GPT-5.4 in both roles against our production baseline across the same system prompts, tool definitions, and harness.
Tasks ranged from routine (rename a button, fix a merge panel) to ambitious: implement tiling window management, reskin an entire UI, debug OG image rendering. This matches our real daily workload. Five team members tested independently: CEO, CTO, and three engineers, each bringing different workflows and expectations.
The AI that evaluated the AI
Here is the part we did not expect to become the story.
After two days of testing, we needed to compile all the feedback (Slack threads, production traces, team impressions) into a structured report for OpenAI. So we asked Captain Capy to do it.
One prompt. Captain searched every Slack channel for mentions of GPT-5.4, pulled aggregate statistics from our ClickHouse traces (latency distributions, token counts, tool call patterns), cross-referenced team sentiment across channels, and produced a 12-page PDF with tables, direct quotes, and specific session traces.
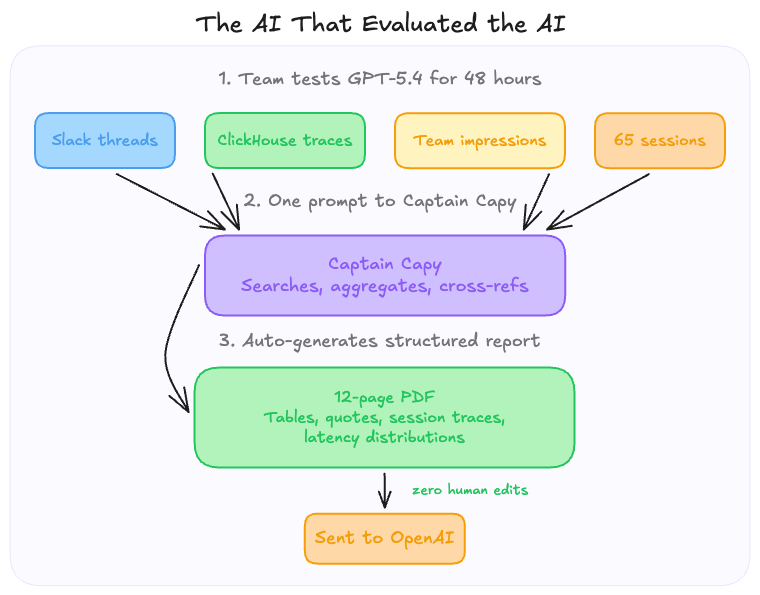
An AI, writing a report about an AI, for the team that builds AI agents. We sent it to OpenAI with zero human edits.
Where GPT-5.4 shines
It is fast. At p95, GPT-5.4 clocked in at ~22 seconds versus ~50 seconds for our baseline. For an orchestration agent making dozens of tool calls per session, that speed compounds quickly. Median latency is comparable (~5.5s vs ~5.7s), but the tail latency improvement means fewer sessions where users are left waiting.

System prompt adherence is excellent. Our prompts are long and detailed, thousands of tokens covering formatting, tool usage, communication style, and guardrails. GPT-5.4 follows them more faithfully than any model we have tested. Where other models drift from instructions over long conversations, GPT-5.4 stays locked in.
Clean code on focused problems. Given a well-scoped, isolated task (implementing Effect.ts Schedule combinators, fixing a specific component) the output is clean, concise, and correct.
| Metric | GPT-5.4 | Baseline (Opus 4.6) |
|---|---|---|
| p95 latency | ~22s | ~50s |
| p50 latency | ~5.5s | ~5.7s |
| Avg output tokens/call | 330 | 587 |
| Total sessions tested | 65 | 1,806 |
| Total LLM calls | 2,256 | 40,106 |
Where it fell short
The review fixing loop
This was the most dramatic finding.
Capy's workflow includes a review step: after Build finishes a task and Captain creates a PR, a Review Agent checks the code. If it finds issues, Captain triages, marking false positives as irrelevant and sending real issues back to Build for fixes.
Our baseline model exercises judgment here. It knows when findings are borderline, when to stop iterating, and when good enough is the right call. GPT-5.4 Captain took every finding at face value and dutifully sent each one back to Build. Each fix sometimes introduced new findings. This created a loop.
On one task, a UI reskin, GPT-5.4 Captain entered six consecutive review-fix cycles:
That loop consumed 164,000 tokens and ~43 minutes. Our baseline handles the same workflow in a single pass because it triages aggressively and bundles remaining fixes together.
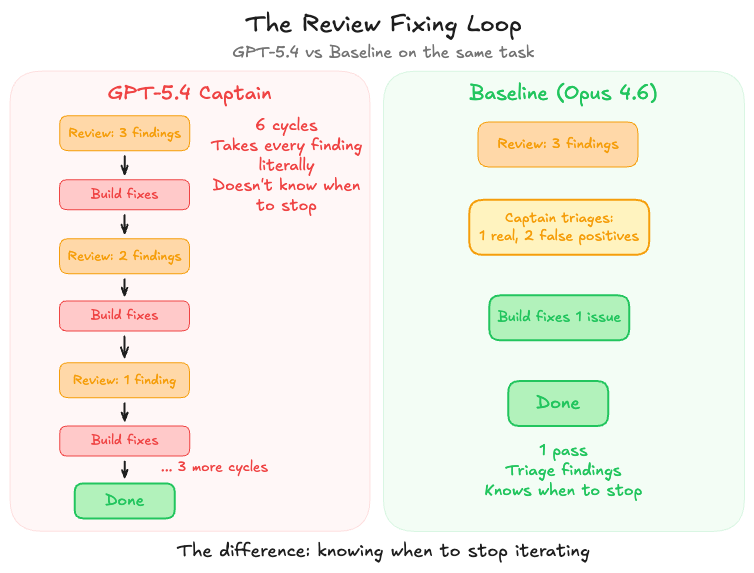
"We expected to see this kind of behavior with our baseline too, but it is somehow smart enough not to go down this path."
Codebase grounding
In a 250K+ line monorepo, you need a model that finds existing patterns and extends them. GPT-5.4 tends to rewrite from scratch rather than integrate with what is already there. It reads extensively (one session logged 104 file reads for just 6 edits, a 17:1 ratio versus the typical 3:1) but struggles to synthesize what it reads into targeted changes.

"The recurring pattern is insufficient codebase grounding. It rewrites rather than integrates, misses existing utilities, and finds fewer instances during search-heavy tasks."
The conservatism problem
We ran the same creative prompt through both models: "reskin our UI with a Warcraft theme." Our baseline produced an ambitious, cohesive overhaul touching design tokens, component primitives, and layout globals. GPT-5.4 did the bare minimum that technically qualifies, and used the X (Twitter) logo as a close button icon instead of building a proper one.
That captures the difference. GPT-5.4 treats creative tasks as mechanical checklists. It does what you ask, but does not bring the initiative that makes an AI agent feel like a collaborator rather than a command executor.
The planner problem
Captain's job is to be a proactive technical architect: explore the codebase, ask clarifying questions, write exhaustive specs, make creative decisions. GPT-5.4 Captain skips clarifying questions, writes thinner specs, and sometimes delegates decisions to Build that Captain should own.
In one session, instead of specifying how to fix an issue, it told the Build agent to "figure out how to fix it using a previous commit." That is not planning, that is punting.
The scorecard
Five team members tested independently and converged on the same assessment:
| Area | Rating |
|---|---|
| Speed | ✅ Excellent, ~2x faster at p95 |
| System prompt adherence | ✅ Strong, best we have seen |
| Code style (isolated tasks) | ✅ Clean and concise |
| Codebase grounding | ❌ Rewrites instead of integrating |
| Long-horizon orchestration | ❌ Review fixing loops |
| Creative planning | ❌ Mechanical, not thoughtful |
| Proactive communication | ⚠️ Too quiet, follows "be concise" too literally |
The speed advantage is real and meaningful. The intelligence on isolated problems is competitive. But for the multi-file, multi-step, judgment-heavy workflows that define AI-native development, there is a gap.
What this means for you
GPT-5.4 is available in Capy today. If your work is speed-sensitive and well-scoped (focused coding tasks, quick edits, problems with clear boundaries) it is a strong option. For complex orchestration, long-horizon planning, and tasks that need creative judgment, our default model remains the better choice.
Every new model we test makes Capy better. The testing process surfaces edge cases in our own agent architecture, and the feedback loop with model providers pushes the whole ecosystem forward.
And the 12-page evaluation report that Captain Capy auto-generated? It was good enough to send directly to OpenAI with zero human edits. If that is not a testament to what AI agents can do today, we do not know what is.
